[Automatic translation by Google]
Please provide your feedback about the website at feedback@apc.iisc.ernet.in
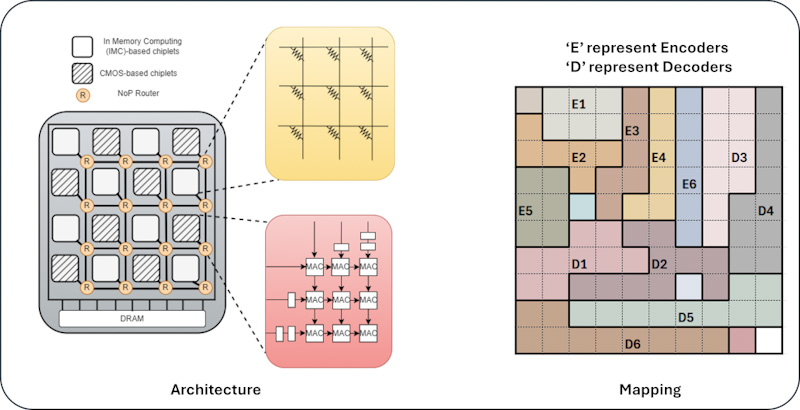
Large language models (LLMs) are used to perform various tasks, especially in the domain of natural language processing (NLP). State-of-the-art LLMs consist of a large number of parameters that necessitate a high volume of computations. Currently, graphics processing units (GPUs) are the preferred choice of hardware platform to execute LLM inference. However, monolithic GPU-based systems executing large LLMs pose significant drawbacks in terms of fabrication cost and energy efficiency. In this work, we propose a heterogeneous 2.5D chiplet-based architecture for accelerating LLM inference. Thorough experimental evaluations with a wide variety of LLMs show that the proposed 2.5D system provides up to 972 improvement in latency and 1600 improvement in energy consumption with respect to state-of-the-art edge devices equipped with GPU.
Publications
1. Jaiswal, Abhi, et al. “HALO: Communication-aware Heterogeneous 2.5 D System for Energy-efficient LLM Execution at Edge.” IEEE Journal on Emerging and Selected Topics in Circuits and Systems (2024).
2. KC, Sharin Shahana, et al. “InDenT: An Energy-efficient 2.5 D System with Heterogeneous Reconfigurable Interconnect for Dense Foundational Models.” IEEE Transactions on Circuits and Systems for Artificial Intelligence (2025).
Faculty: Sumit Kumar Mandal