[Automatic translation by Google]
Please provide your feedback about the website at feedback@apc.iisc.ernet.in
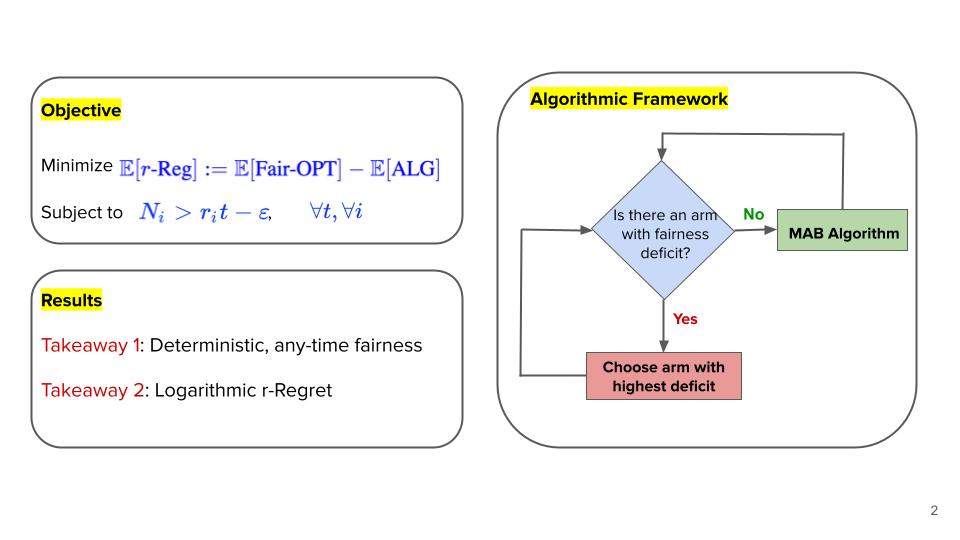
Fairness is a key requirement in all decision making settings. This work focuses on achieving fairness in online learning algorithms. In particular, we study an interesting variant of the stochastic multi-armed bandit problem (MAB) which we call “Fair-MAB,” where, in addition to minimizing expected regret, the algorithm must also ensure that each arm is pulled a certain pre-specified fraction of time-steps. The performance of the algorithm is evaluated based on the regret and fairness guarantees. We show that our algorithm achieves O(log{T}) regret. The proposed class of algorithms remarkably provides a strong deterministic fairness guarantee that holds uniformly over the time horizon. Both the regret and fairness guarantees of our algorithm improve upon the best-known results in the literature.
Reference:
Vishakha Patil, Ganesh Ghalme, Vineet Nair, Y. Narahari. Achieving Fairness in the Stochastic Multi-armed Bandit Problem. To appear in: Journal of Machine Learning Research (JMLR), 2021.
The above paper is an expanded and enhanced version of the following paper which contained the preliminary results:
Vishakha Patil, Ganesh Ghalme, Vineet Nair, Y. Narahari. Achieving Fairness in the Stochastic Multi-armed Bandit Problem. AAAI-2020. Pages 5379-5386.
Faculty: Y. Narahari, CSA