Please provide your feedback about the website at feedback@apc.iisc.ernet.in
Speech articulation varies across speakers for producing a speech sound due to the differences in their vocal tract morphologies, though the speech motor actions are executed in terms of relatively invariant gestures.
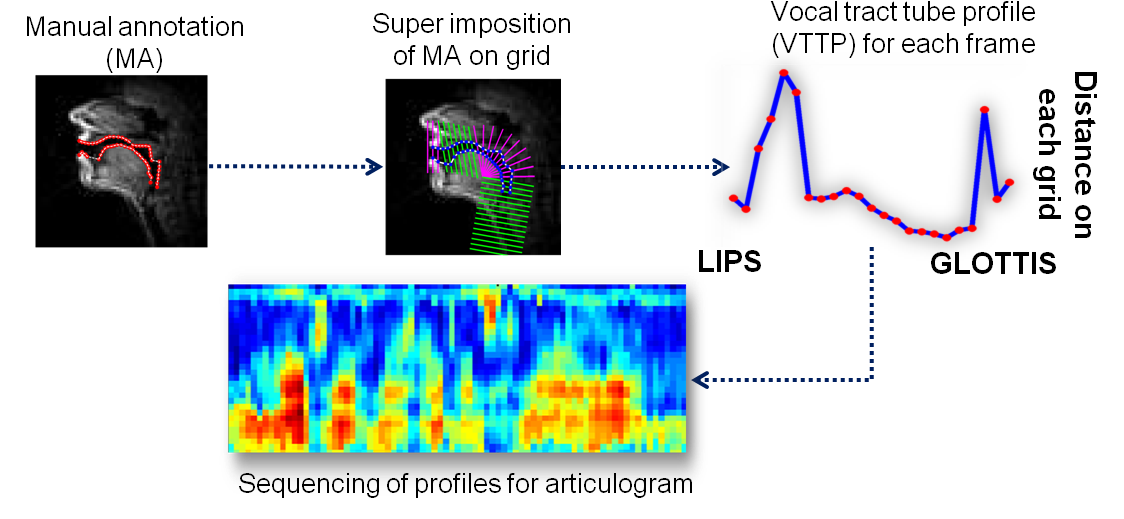
While the invariant articulatory gestures are driven by the linguistic content of the spoken utterance, the component of speech articulation that varies across speakers reflects speaker-specific and other paralinguistic information. For this purpose, a new representation, called articulogram, is computed using the air-tissue boundaries in the upper airway vocal tract and the Maeda grid on the real-time magnetic resonance imaging video frames. The articulograms from multiple speakers are decomposed into the variant and invariant aspects when they speak the same sentence. The variant component is found to be a better representation for discriminating speakers compared to the speech articulation which includes the invariant part.