[Automatic translation by Google]
Please provide your feedback about the website at feedback@apc.iisc.ernet.in
Due to increase in the number of sources of data, research in cross-modal matching is becoming an increasingly important area of research.
It has several applications like match- ing text with image, matching near infra-red images with visible images (eg, for matching face images captured during night-time or low-light conditions to standard visible light images in the database), matching sketch images with pictures for forensic applications, etc.
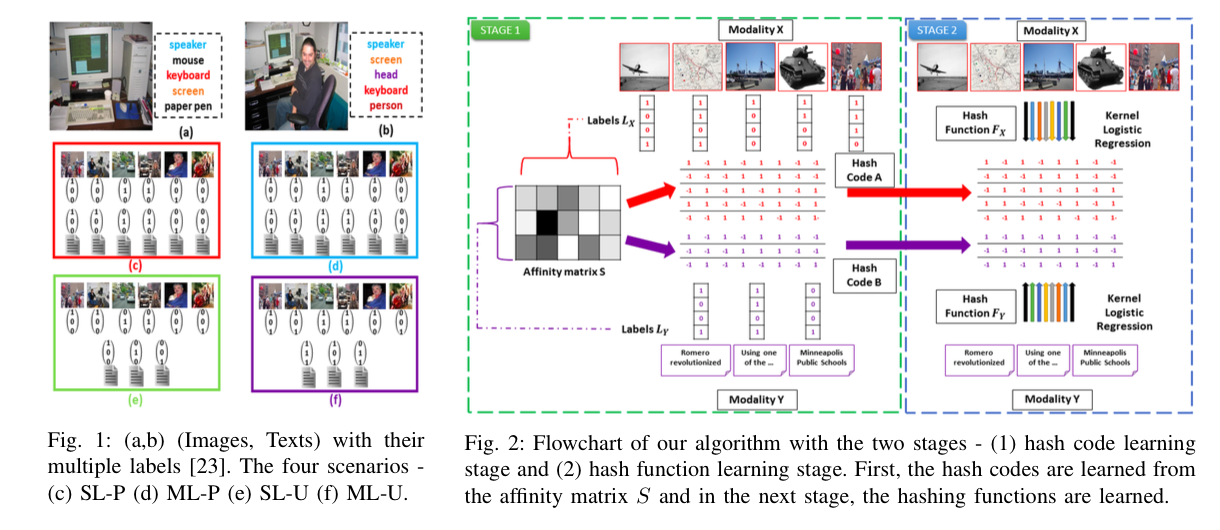
We are developing novel algorithms for this problem, which is extremely challenging, due to significant differences between data from different modalities. Specifically, we have developed a generalized semantic preserving hashing technique for cross-modal retrieval algorithms, which can work seamlessly for single and multi-label data, as well as in paired and unpaired scenarios. The algorithm obtained state-of-the-art performance in different applications.