[Automatic translation by Google]
Please provide your feedback about the website at feedback@apc.iisc.ernet.in
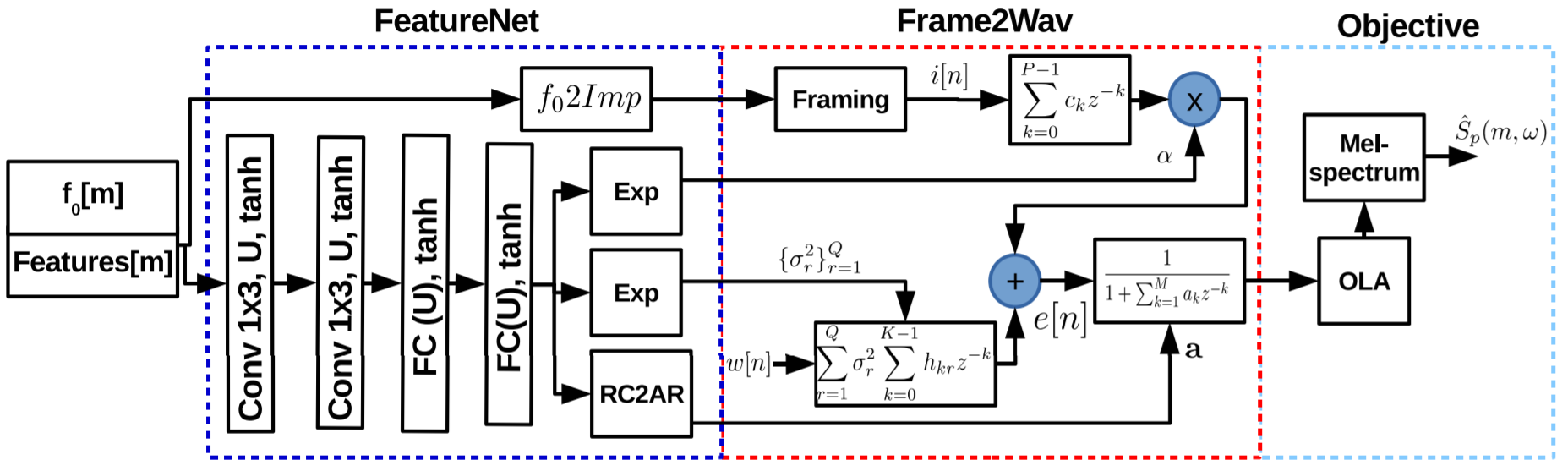
A reduced-complexity speech synthesizer is developed by reformulating the source-filter model of speech where the excitation signal is modeled as a sum of a pitch-dependent impulse train and colored noise. The parameters of the reformulated source-filter model are predicted using a neural network, referred to as SFNet. The network parameters are learnt by training the network using l1-error between the log Mel-spectrum of the predicted waveform and that of the ground-truth waveform. We demonstrate that there is a significant reduction in the memory and computational complexity compared to the state-of-the-art speaker independent neural speech synthesizer without any loss of the naturalness of the synthesized speech.
https://spire.ee.iisc.ac.in/spire/papers_pdf/Achuth_SPLetters_2020.pdf
https://araomv.github.io/SFNet/